

Cuando se ejecutan aplicaciones en AWS, los problemas de rendimiento suelen provenir de lugares inesperados. Una carga de trabajo puede estar diseñada para escalar, pero los cuellos de botella ocultos en los límites de computación, bases de datos, redes o incluso de servicio pueden frenarla. Detectar estos cuellos de botella no consiste en mirar un único gráfico de la CPU. Se trata de comprender la arquitectura en conjunto y determinar dónde se generan los retrasos o los problemas de capacidad.
En este blog, repasaremos cómo detectar los cuellos de botella en los entornos de AWS, cubriendo las capas en las que se producen con más frecuencia, las herramientas que necesita para detectarlos y los pasos prácticos para resolverlos.
Comprender los cuellos de botella en las arquitecturas de AWS
En las arquitecturas distribuidas en la nube, los cuellos de botella surgen cuando un componente o recurso limita la velocidad de transferencia en relación con la demanda. A diferencia de los entornos monolíticos, los cuellos de botella pueden adoptar muchas formas en AWS. He aquí algunos ejemplos:
• Límites de computación: instancias, contenedores o funciones Lambda que se quedan sin CPU, memoria o concurrencia
• Límites de almacenamiento/base de datos: consultas de RDS en espera de bloqueos, particiones de DynamoDB estranguladas o puntos calientes de la clave S3
• Problemas de red: estrangulamiento de solicitudes del gateway de API, límites de ancho de banda del gateway de NAT o alta latencia del tráfico entre regiones
• Cuotas de servicio: límites de AWS integrados (límites de solicitud de API, límites de concurrencia de Lambda)
• Defectos en el diseño de la aplicación: llamadas de servicio síncronas, sin almacenamiento en caché ni demasiada dependencia de una única base de datos
Lo que hace que los cuellos de botella de AWS sean complicados es que a menudo surgen a escala o bajo cargas de trabajo específicas, no durante el tráfico diario. Por eso la detección depende de una buena observabilidad y de un proceso estructurado.
Construir los cimientos con la observabilidad
Antes de poder detectar los cuellos de botella, su sistema debe proporcionar visibilidad. AWS le ofrece varias capas de observabilidad out-of-the-box:
• Métricas y logs de AWS CloudWatch: visibilidad de referencia del rendimiento del servicio. Esto es rítico para la CPU, la memoria (a través del agente de CloudWatch), la E/S del disco y la velocidad de transferencia de la red.
• AWS X-Ray: seguimiento distribuido para el análisis de la latencia entre servicios.
• Logs de flujo de VPC: información a nivel de red sobre patrones de tráfico, pérdidas de paquetes y limitaciones de velocidad de transferencia.
• Métricas específicas del servicio: DynamoDB (estrangulamiento de RCU/WCU), S3 (latencia de la solicitud), Lambda (duración y recuentos de arranque en frío), RDS (tiempos de ejecución de la consulta, porcentaje de aciertos de la caché del búfer).
Muchos equipos también confían en herramientas externas para el monitoreo del rendimiento de aplicaciones (APM) como ManageEngine Applications Manager para correlacionar las métricas de AWS con el rendimiento a nivel de aplicación. Sin esta visibilidad, los cuellos de botella permanecen invisibles hasta provocar interrupciones.
Un proceso paso a paso para detectar los cuellos de botella
La forma más efectiva de localizar los cuellos de botella es seguir un proceso sistemático.
Paso 1: perfilar las cargas de trabajo
Comience midiendo el rendimiento de referencia bajo una carga normal y un pico. Esto incluye la latencia, la velocidad de transferencia y las tasas de error. Disponer de una línea de base le permite distinguir entre la variación esperada y las anomalías reales.
Paso 2: aislar los componentes
Divida el sistema en planos. Examine cada capa por separado antes de comprobar los flujos de extremo a extremo.
A. Capa de computación
• EC2: CPU alta (>80%), límites de red/EBS alcanzados
• Lambda: se alcanzan los límites de concurrencia, arranques en frío demasiado frecuentes
• ECS/EKS: pods estrangulados, desalojados o privados de CPU/memoria
B. Capa de datos
• RDS/Aurora: largos tiempos de consulta, esperas de bloqueo, IOPS de almacenamiento al máximo
• DynamoDB: particiones en caliente, lecturas/escrituras estranguladas
• S3: picos de latencia, puntos calientes de nombramiento de la clave secuencial
• ElastiCache: demasiados desalojos, alta tasa de fallo de caché
C. Capa de red
• Gateway de API: Errores 429 (estrangulamiento), alta latencia de la solicitud
• Gateway de NAT: saturación del ancho de banda, costos elevados
• VPC/Red: latencia entre zonas/regiones, pérdidas de paquetes.
Paso 3: analizar el uso de los recursos
Cada servicio tiene signos reveladores de problemas. Analícelos para comprender mejor los cuellos de botella:
• EC2 → Alta CPU sostenida, EBS estrangulado o topes de red.
• Lambda → Uso elevado de memoria, arranques en frío frecuentes o estrangulamiento.
• Contenedores → Pods privados de recursos o desalojados.
• RDS → Alta latencia de consulta, esperas de bloqueo, IOPS que alcanzan los límites.
• DynamoDB → Solicitudes estranguladas o acceso desigual a la partición.
• S3 → Picos de latencia con nombramiento secuencial de la clave.
• ElastiCache → Tasa de fallo de caché o picos de desalojo.
• Red → Tráfico cruzado AZ, cuellos de botella de NAT, estrangulamiento del gateway de API.
Paso 4: rastrear las latencias
Use AWS X-Ray o el seguimiento distribuido para trazar cómo se mueven las solicitudes entre los servicios. Esto suele revelar problemas como una dependencia descendente lenta, bucles de reintento o llamadas a servicios síncronos que convierten un retraso en una ralentización de todo el sistema.
Cuellos de botella comunes a nivel de servicio en AWS
Aunque cada carga de trabajo es diferente, algunos cuellos de botella aparecen repetidamente entre los clientes de AWS:
• EC2: límites de ancho de banda de la red en los tipos de instancia más pequeños o límites de velocidad de transferencia de EBS que estrangulan silenciosamente las cargas de trabajo con mucho almacenamiento
• Lambda: límites de concurrencia en toda la cuenta que provocan estrangulamiento, en especial en escenarios de ráfagas de tráfico
• RDS/Aurora: una única instancia primaria sobrecargada con lecturas y escrituras, que se soluciona al añadir réplicas o cambiando al modelo de escalado de Aurora
• DynamoDB: mal diseño de la clave de partición que crea particiones en caliente
• S3: Nombres de la clave secuenciales o con patrones que canalizan las solicitudes a una única partición de almacenamiento
• Gateway de API: límites regionales de solicitudes o estrangulamiento por cliente que provocan errores 429
• Gateway de NAT: cuellos de botella ocultos en el ancho de banda y costos crecientes al gestionar un gran tráfico saliente
Reconocer estos patrones hace la resolución de problemas más rápida, ya que puede probar los posibles culpables con antelación.
Técnicas avanzadas de diagnóstico
A veces los dashboards habituales no son suficientes. En esos casos, las técnicas avanzadas ayudan a descubrir cuellos de botella más profundos:
• Ingeniería del caos: inyecte fallos o picos de carga (utilizando herramientas como AWS Fault Injection Simulator) para revelar puntos de estrangulamiento ocultos.
• Prueba de carga sintética: simule cargas de trabajo concurrentes con Locust, JMeter o Gatling contra endpoints de API o bases de datos backend. También puede utilizar técnicas de monitoreo sintético en soluciones de monitoreo como Applications Manager.
• Análisis de correlación: emplee métodos estadísticos (correlación cruzada, regresión) para identificar los indicadores rezagados que preceden a los cuellos de botella (por ejemplo, el aumento de la longitud de la cola correlacionado con la latencia descendente).
• Análisis de la señal de costos: los picos de costos inesperados suelen indicar ineficiencias ocultas, por ejemplo, repetidos reintentos en las solicitudes PUT de S3 o un aprovisionamiento excesivo de DynamoDB.
Estas técnicas hacen que la detección pase de ser reactiva a proactiva.
Antipatrones arquitectónicos que provocan cuellos de botella
Muchos cuellos de botella de AWS rastrean los antipatrones arquitectónicos en lugar de dejarlo al azar. Algunos de los más dañinos son:
• Bases de datos monolíticas: centralización excesiva del estado en una única instancia de RDS
• Encadenamiento síncrono: llamadas de API en serie entre servicios en lugar de desacoplamiento basado en eventos
• Falta de una estrategia de almacenamiento en caché: dependencia excesiva de los almacenes de datos de origen sin intermediarios de Redis/CloudFront
• Conocimiento inadecuado de la cuota: diseñar sin tener en cuenta los límites blandos/duros de AWS por región
• Directivas de IAM ineficaces: evaluación granular que provoca una latencia excesiva en el plano de control
Evitar estos patrones suele ser más efectivo que combatirlos a posteriori.
Corregir y prevenir los cuellos de botella
Una vez identificado un cuello de botella, puede aplicar soluciones específicas:
• Ajustes de la escala: transicione del autoescalado reactivo al escalado predictivo impulsado por modelos de ML (por ejemplo, autoescalado EC2 con escalado predictivo).
• Sustitución del servicio: reemplace las API síncronas por mensajería asíncrona (SQS/Kinesis).
• Fragmentación y partición: redistribuya la carga de trabajo entre las particiones de DynamoDB o los fragmentos de la base de datos.
• Caché y CDN: descargue las consultas repetidas con ElastiCache, almacenamiento en caché perimetral con CloudFront.
• Refactorización arquitectónica: adopte arquitecturas basadas en eventos o microservicios para minimizar la interdependencia.
Para evitar que se repita, integre la detección continua con la detección de anomalías de CloudWatch, AWS DevOps Guru o soluciones de monitoreo de terceros como Applications Manager. Para las cargas de trabajo híbridas, también puede beneficiarse del monitoreo de nube híbrida.
Optimice sus cargas de trabajo de AWS con Applications Manager
Detectar cuellos de botella en AWS no consiste tanto en perseguir métricas aisladas como en construir una visión holística de toda la arquitectura. Con la observabilidad adecuada, un análisis estructurado y el conocimiento de los límites específicos del servicio, se pueden identificar los problemas de rendimiento antes que afecten a los usuarios finales.
Aunque las herramientas nativas para el monitoreo de AWS proporcionan bases seguras, muchos equipos se benefician de una solución de monitoreo unificada como ManageEngine Applications Manager, que consolida métricas, trazas y alertas en una sola plataforma. Al usar una solución de este tipo en su flujo de trabajo, puede pasar de la extinción reactiva a la gestión proactiva del rendimiento. De esta forma, mantiene sus cargas de trabajo de AWS resilientes, eficientes y listas para escalar.
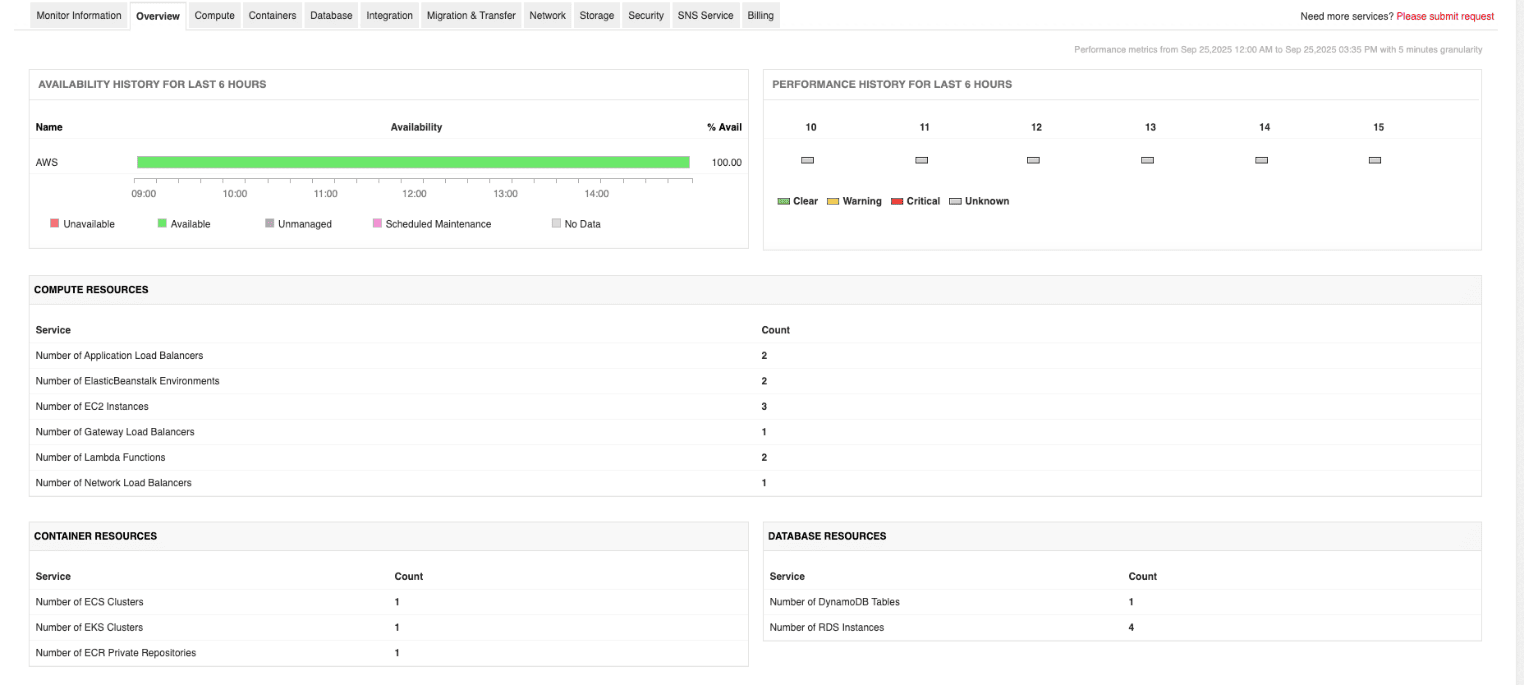
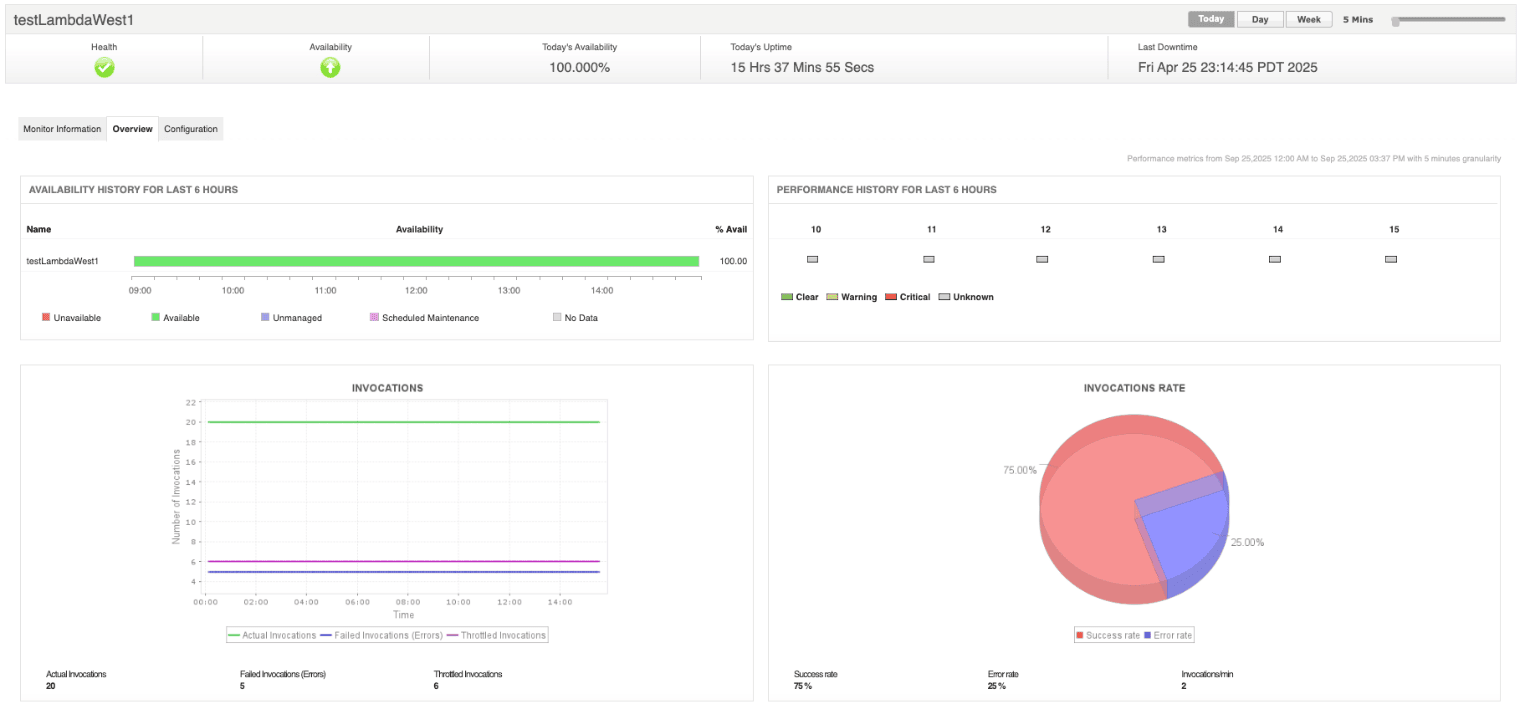
Las principales funciones de detección de cuellos de botella de ManageEngine Applications Manager incluyen:
• Monitoreo unificado de AWS: consolida el monitoreo de EC2, RDS, S3, ELB, Lambda, DynamoDB y más. Esto permite identificar los cuellos de botella en los recursos de computación, almacenamiento, bases de datos, sin servidor y contenedores desde un único dashboard.
• Monitoreo del rendimiento de aplicaciones (APM): proporciona diagnósticos a nivel de código con mayor profundidad. Revela la latencia, las transacciones lentas y las llamadas a la API fallidas examinando a detalle funciones, consultas o flujos de solicitud específicos.
• Monitoreo sintético y de usuarios reales (RUM): analiza tanto las interacciones simuladas como las reales de los usuarios. Correlaciona los retrasos en el front-end, la red y el back-end para descubrir dónde se produce la degradación dentro del stack de AWS.
• Mapas de servicio de la aplicación y mapeo de dependencias: visualiza las interdependencias en las arquitecturas de nube. Esto permite localizar rápidamente los cuellos de botella en entornos de varios niveles y microservicios.
• Análisis de causa raíz y reparación automatizada: diagnostica los problemas subyacentes con dashboards dinámicos y sistemas de gestión de fallos que pueden disparar acciones correctivas para reducir el tiempo medio para resolver (MTTR).
Applications Manager se integra con AWS CloudWatch para agregar métricas, eventos y logs al complementar la información nativa de AWS con funciones de análisis y visualización más detalladas. Puede monitorear algo más que la infraestructura. Es compatible con bases de datos, contenedores (EKS, ECS, Kubernetes) y entornos híbridos. Ayuda a los equipos a detectar la contención de recursos, las consultas lentas y los errores de configuración en todo el stack.
Para ver cómo funciona en la práctica, puede contactarnos para realizar una demostración y generar una prueba de Applications Manager.


